python爬虫理论知识
大家好我是羔羊,今天和大家一起探讨下python里面的爬虫的大概流程和思路。
在讲解爬虫的时候,我们首先要了解的就是:
网络与用户的交互本质上是数据的交互是传参的交互而爬虫恰好能够让我们可以从网络上面更加快速便捷的获取到我们所需要的东西这就是网络爬虫的作用。
当然我们在使用爬虫访问的时候也要对自己的行为进行约束,不然会对他人造成一定的影响,比如说:
1、过于快速或者频密的网络爬虫会对服务器产生巨大的压力,导致网站对你进行封锁ip。
2、该课件仅用于网络爬虫教学 切勿用于其他用途
网络爬虫的基础流程
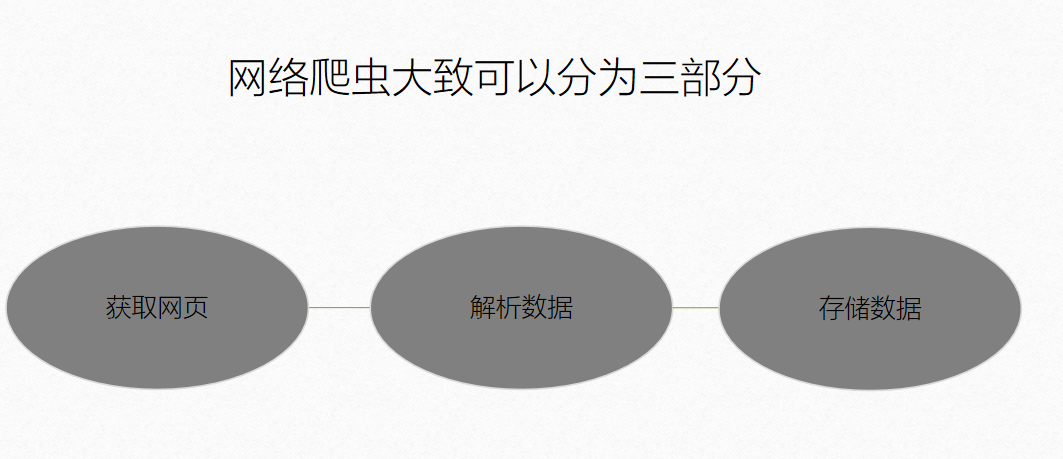
三个流程的技术实现
1、获取网页
获取网页所用到的库:requests、urllib、selenium
获取网页的进阶技术:多进程多线程抓取、登陆抓取、突破ip封禁和服务器抓取
2、解析数据
解析网页的基础技术:re正则表达式、BeautifulSoup、lxml
解析网页的进阶技术:解决中文乱码
3、存储数据
存储数据的基础技术:存入txt文件
存储数据的进阶技术:存入MYSQL数据库和存入MongoDB数据库。
在心里面有了个大概的思路以后我们就可以来编写自己的第一个网络爬虫了。



