python网络爬虫BeautifulSoup
大家好我是羔羊!今天给大家分享下解析数据里面的BeautifulSoup,在我们爬取网页的时候,经常需要在网页中获取特定的一些数据,这个时候就用到了我们的BeautifulSoup库。
BeautifulSoup的下载
在这里有一个坑,你直接在cmd里面输入pip install BeautifulSoup 是会报错的
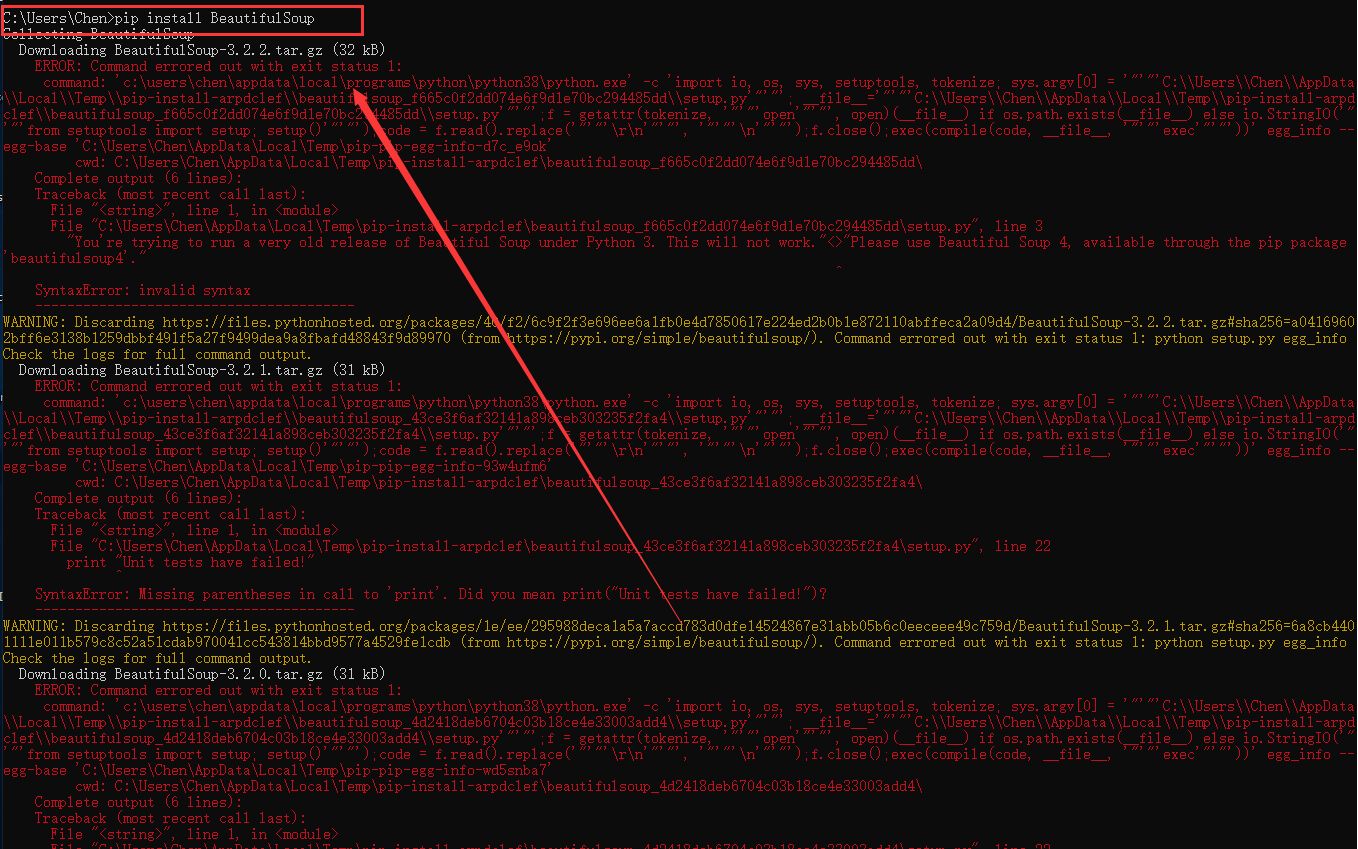
因为他在python里面的库名虽然叫BeautifulSoup,但是在下载的时候需要用bs4来表示BeautifulSoup4,在这里我们需要用指令:pip install bs4 -i https://pypi.douban.com/simple/
来进行下载,下载完成以后用 pip list 来进行查看
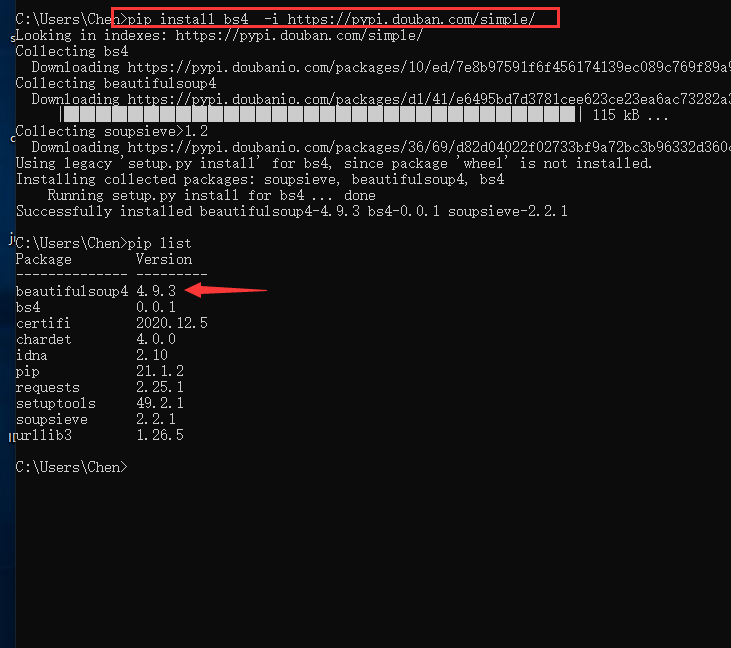
很明显已经下载完成了,接下来就开始编写代码了。
BeautifulSoup代码案例
在这里我们依旧用top250这个网址来进行讲解,我们今天爬取的是Top250里面的电影名字和导演主演等信息内容首先上代码
import requestsfrom bs4 import BeautifulSoup
def get_movies():
headers = {
'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36'
,'Host':'movie.douban.com'
}
1 | movie_list = [] |
1 | for i in range(0,1): |
``
1 | div_list = soup.find_all('div',class_ = 'bd' ) |
movies = get_movies()
在这里我们将整个爬虫给做成了一个方法,这样子更加方便以后我们对代码的复用性
首先依旧是导入模块
import requestsfrom bs4 import BeautifulSoup
接下来伪装自己的python将其伪装成一个浏览器
`headers = {`
`'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36'`
`,'Host':'movie.douban.com'`
`}`
这里因为还没讲怎么保存到本地,只是打印出来,所以就用两个列表来进行保存
movie_list = []
a = []
b = []
然后是进行网页的爬取
link = ‘https://movie.douban.com/top250?start=' + str(i*25)
在这里说一句,我这里是直接爬取了10页的数据,所以添加了
for i in range(0,10):
timeout = 10
表示连接的时间是10秒
soup = BeautifulSoup(r.text,”lxml”)
表示的是将文件以BeautifulSoup的方式来进行解析,解析成lxml的格式
div_list = soup.find_all(‘div’,class_ = ‘hd’ )
这句话要结合网站来进行理解
首先打开网址:https://movie.douban.com/top250
然后F12选择查看器在这里我们可以看到整个网页的代码,然后我们使用查看器左侧的箭头选择需要爬取的内容
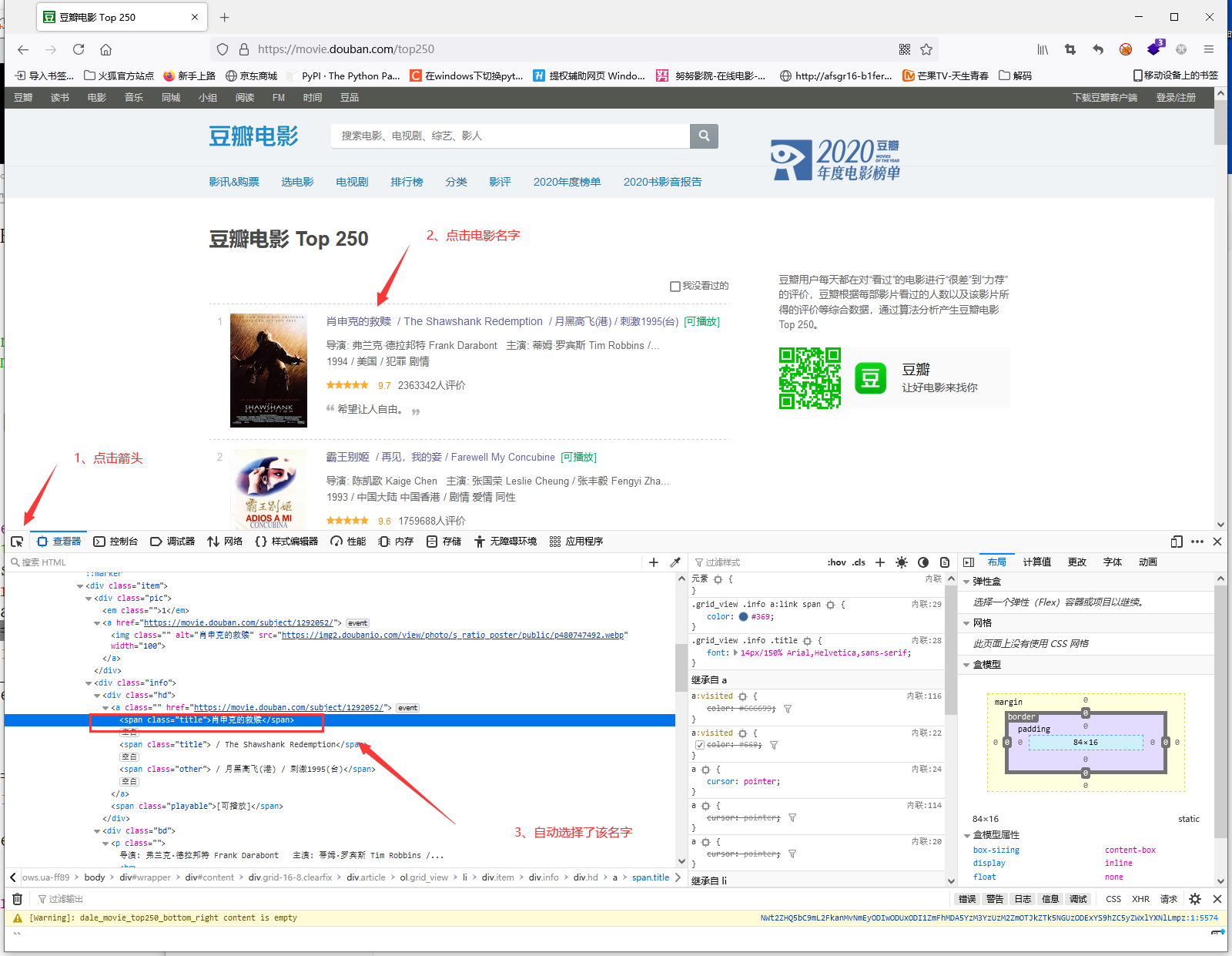
然后我们来分析他的代码结构
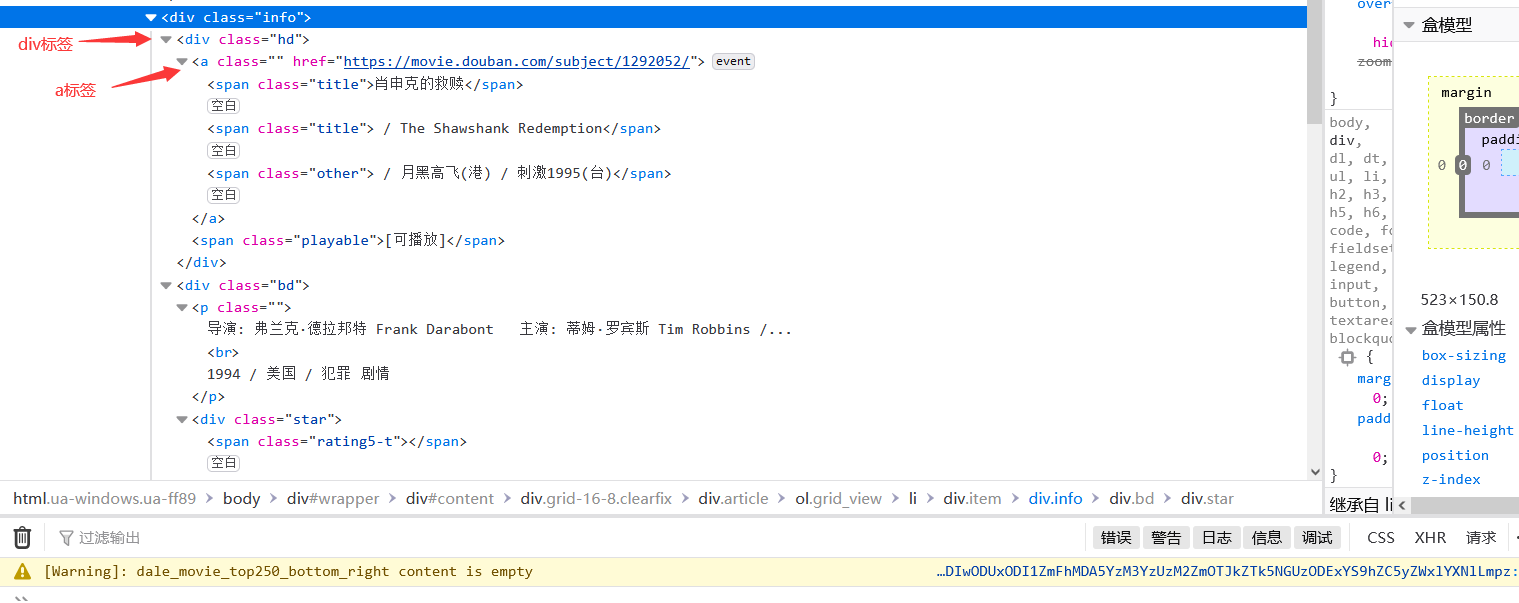
发现他们的内容都在一个a标签里面,也在同一个div标签里面,在这里大家可以尝试点击别的电影名字,会发现他们的结构是一模一样的

所以我们需要的就是python帮助我们获取这几个标签里面的内容,这里我们就选择获取div标签里面的内容,但是这里我们可以看到有很多的div标签,具体获取哪一个呢?这时候我们可以看到旁边会有一个class = “hd”
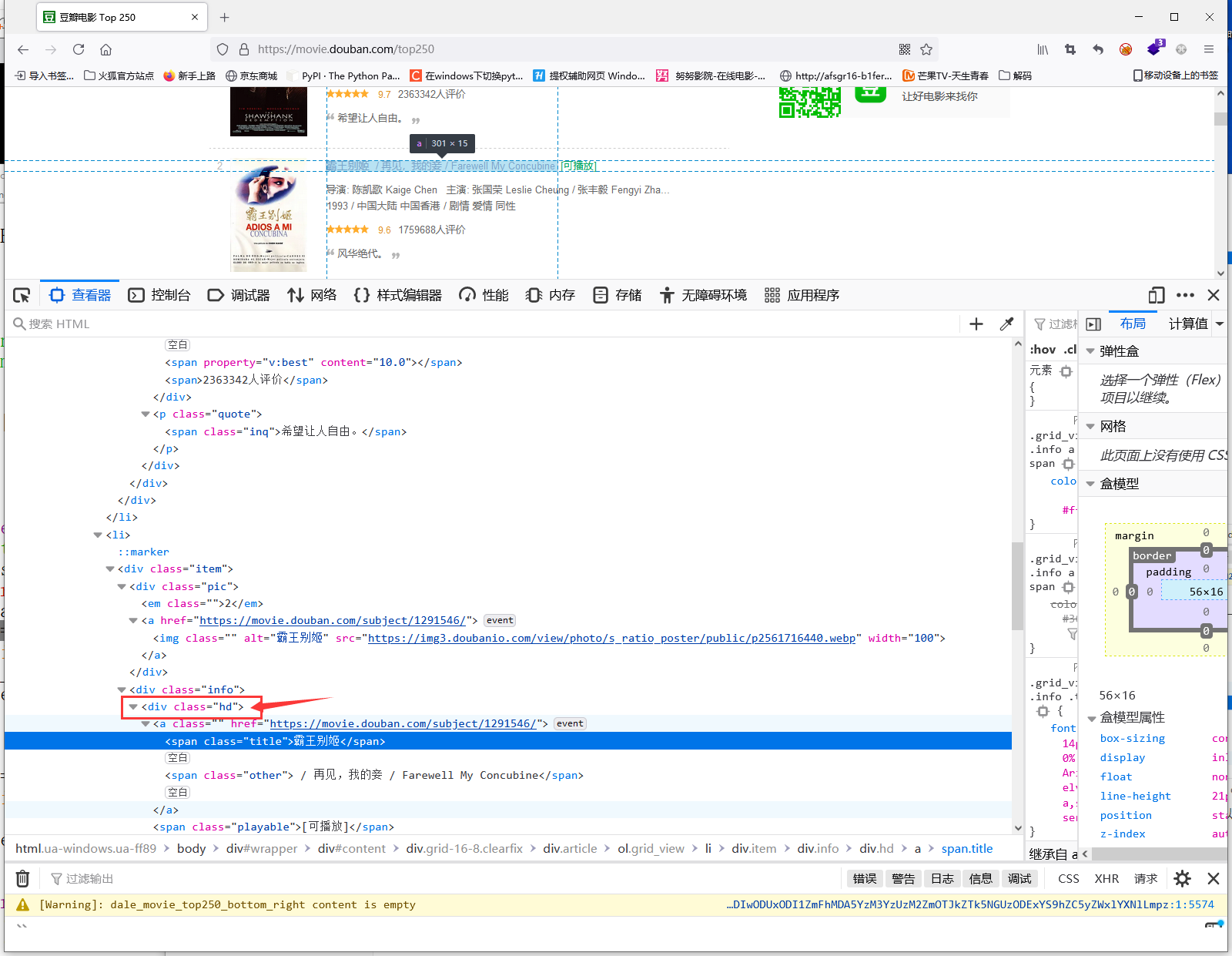
它的class属性就是我们用来识别你获取的是哪一个div里面的内容的标志。
div_list = soup.find_all(‘div’,class_ = ‘hd’ )
表达的意思就是这个网页里面所有的class属性为hd的div标签
这样子我们就可以获取到所有的电影名字了,但是要注意,在这个标签里面也有很多的内容,也有其他的一些标签,那么我们又是如何知道我们选中的就是电影名字呢?
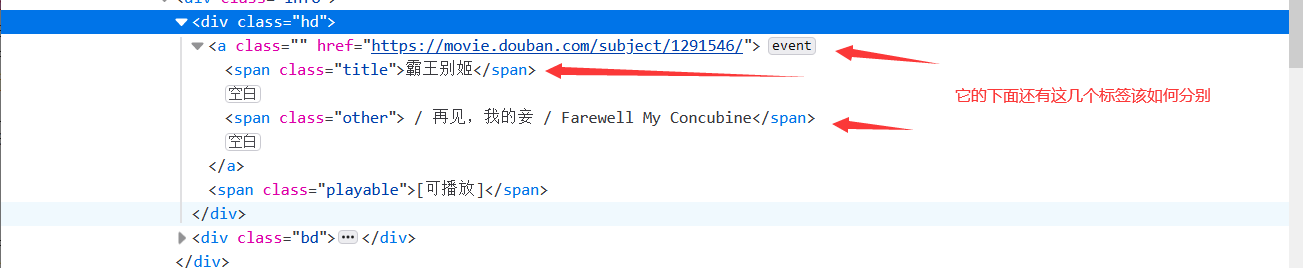
我们就可以通过它的具体标签span来进行获取,因为我们只是获取里面的文字,所以这里需要加上.text来获取里面的内容
movie_name = name.span.text
这里要讲一下为什么要用
for name in div_list:
因为你获取的是所有的电影名字的标签,所以会有多个,那么我们就需要去每一个里面进行筛选,所以需要用遍历来进行操作
1 | div_list = soup.find_all('div',class_ = 'bd' ) |
这里的内容和上面的是一样的,大家可以参照上面自己进行分析
b = b[1:]这一步的意思是去掉列表的第一位
打完收工!



