python网络爬虫Selenium
大家好!我是羔羊,今天和大家一起探讨下关于selenium库的使用和下载
selenium的下载
首先我们需要下载selenium这个库,在这里直接输入代码: pip install selenium -i https://pypi.douban.com/simple
就可以下载完成了
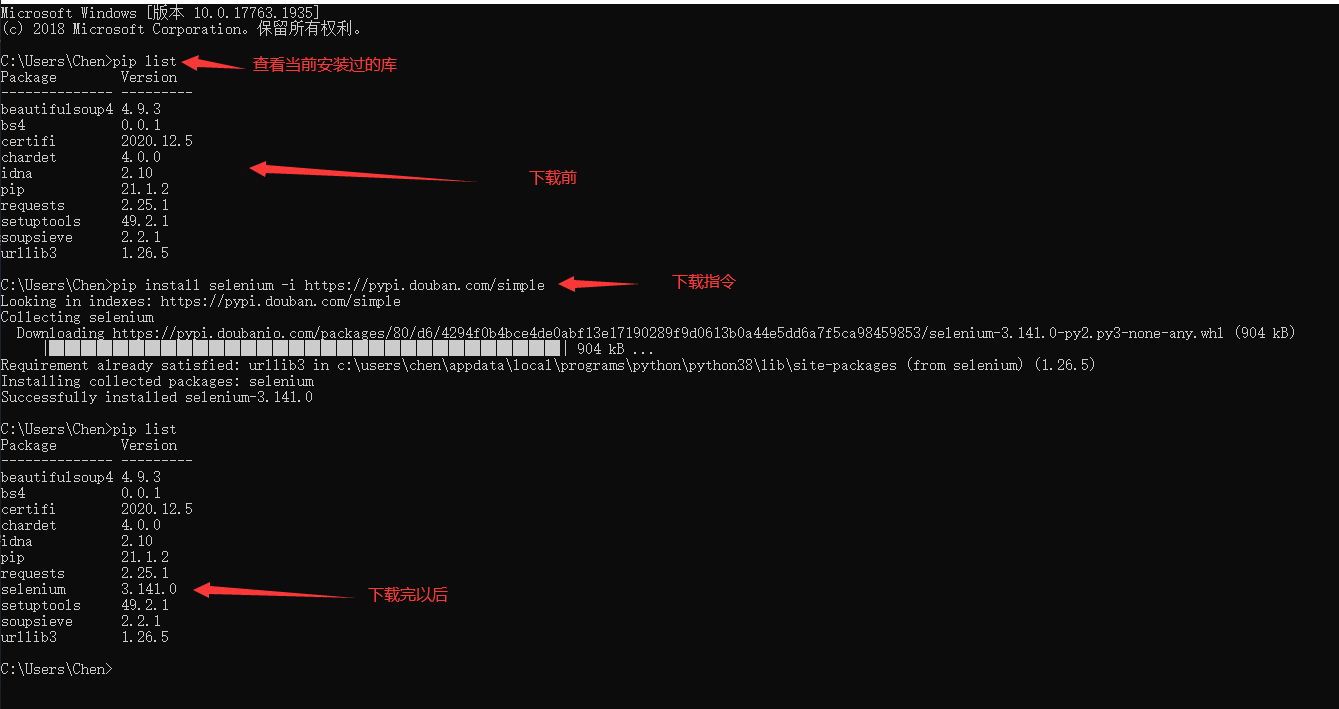
在这里要注意的是出来库以外,我们还需要安装一个插件用来自动开启浏览器进行内容的爬取,所以在这里给大家找了一个别人搭建的下载的地方:
https://github.com/mozilla/geckodriver/releases
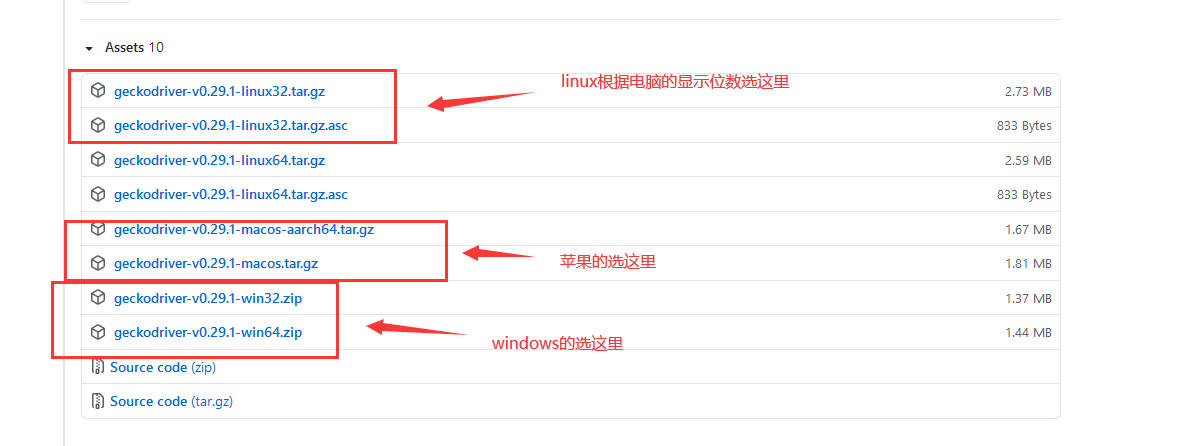
我选择的是最后面的win64的版本,这里也用他作为例子进行讲解:
首先解压缩获得一个叫geckodriver.exe的程序,然后找到火狐浏览器点击右键选择打开文件所在的位置
然后将geckodriver.exe放入到该目录位置
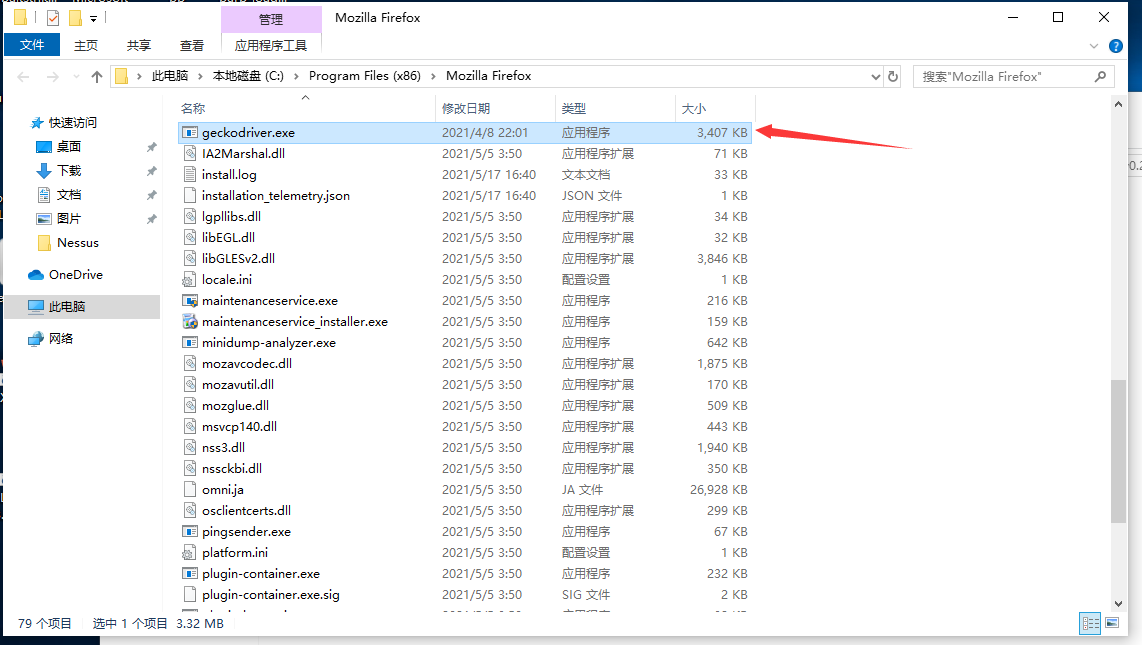
基本就可以了,这里要注意的是一定要用火狐浏览器,因为我的这个插件是配的火狐浏览器的。
好了之后我们就可以写一个简单的代码来尝试运行自己的selenium程序了。
selenium的简单使用
首先我们先尝试运行程序打开百度网页:
from selenium import webdriver
'''网络驱动程序 webdriver 可执行路径 executable_path'''
driver = webdriver.Firefox(executable_path = r"C:\Program Files (x86)\Mozilla Firefox\geckodriver.exe" )driver.get("http://www.baidu.com")
这三行代码,我们一行行来解释
from selenium import webdriver
导入selenium库并且给它取个外号为webdriver
driver = webdriver.Firefox(executable_path = r"C:\Program Files (x86)\Mozilla Firefox\geckodriver.exe" )
通过我们的geckodriver.exe程序来打开火狐浏览器 “C:\Program Files (x86)\Mozilla Firefox\geckodriver.exe” 表示的是这个程序所在的路径,大家请自行替换,小写的r表示的意思是,保持字符原始值的意思,因为python里面字符串中\有转义的含义,如\t可代表TAB,\n代表换行,所以我们需要采取一些方式使得\不被解读为转义字符。
driver.get("http://www.baidu.com")
你要去的目标网址
当你看到出现了一个这样子的页面,那么你的程序就运行成功了
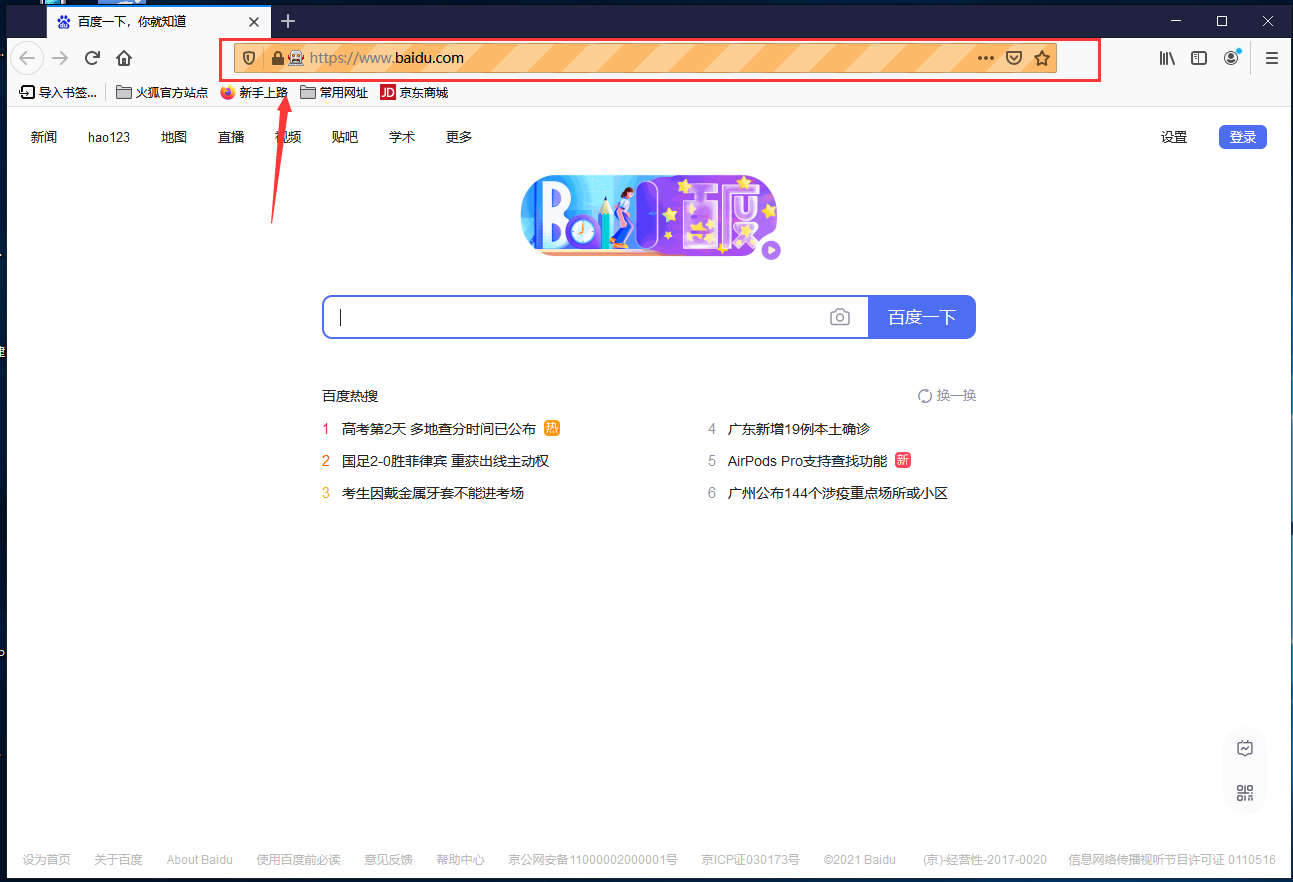
打完收工!下一篇给大家讲解下selenium在top250的使用方式



